
Me oleme just praegu toimuva infotehnoloogilise revolutsiooni tunnistajad, kuid me ei tea, kuhu tehnoloogias ja ühiskonnas toimuvad muutused välja viivad. Arvatakse isegi, et peagi võtavad arvutid inimeste üle võimu. Igatahes ei ole infotehnoloogia põhjustatud suured muutused ühiskonnas veel lõppenud. Me võime siin kasutada analoogiat tööstusrevolutsiooniga, mis toimus kahe sajandi eest tänu aurumasina leiutamisele ja mille oluliseks osaks oli esialgu ka raudteetranspordi ning hiljem autode areng. See ei ole kogu tõde. Sellega kaasnesid uued ohud inimestele: aastas saab üksnes autoõnnetustes surma ligi 1,3 miljonit ja vigastada kuni 50 miljonit inimest. Aurumasina asemel on tänapäeva muutuste põhjustajaks arvuti. IT-revolutsiooni oluliseks osaks on inimkonna sidumine küberuumis peaaegu hetkeliselt leviva info kaudu. Ka siin on omad ohud paratamatud. Millised need on? Kas tasub kõike arvutite intelligentsuse kaela ajada?
Tehismõistuse algus ja selle kriisid
Niipea kui möödunud sajandi keskel olid arvutid kasutusele võetud, mõistsid targemad matemaatikud, et nende abil saab infot töödelda põhimõtteliselt igal viisil, seega ilmselt ka nii, nagu seda teeb inimaju. Selle kohta avaldasid arvamust Alan Turing, John von Neumann, Aleksander Kolmogorov ja teised maailma parimad matemaatikud. Ameerika matemaatik Norbert Wiener kirjutas mitu raamatut selle kohta, kuidas infot kasutatakse sihipärases tegevuses, seda nii tehnikas, bioloogilistes kui ka sotsiaalsetes süsteemides. Ta andis sellele valdkonnale nimetuseks küberneetika. See nimetus jäi pikaks ajaks vene keeles tähistama informaatikat ja osalt ka tehismõistust.
Noored teadlased, eelkõige John McCarthy ja Marvin Minsky, hakkasid innukalt tehismõistuse probleemidega tegelema. Kuid loodetud kiire edu jäi tulemata. Lühidalt võib öelda, et tehismõistuse vallas arendati välja palju meetodeid, mis osutusid kasulikuks heade programmide loomisel, kuid mõistus ise on seni ehitamata.
Tehismõistuse uurimisvaldkonna käekäik on olnud nagu Ameerika mäed: kord kõrgele üles, kord järsu langusega sügavale alla. Näiteks võib tuua briti tehismõistuse isa ning Eesti sõbra Donald Michie käekäigu. Töötades koos Alan Turingiga Bletchley Parki uurimiskeskuses koodimurdmise alal, alustas Donald tehismõistuse uuringuid. Ta asutas Edinburghis tehismõistuse uurimislabori, hakkas välja andma kogumikku „Machine Intelligence“, mis sai tuntuks üle maailma.

1973. aastal algas esimene tehisintellekti kriis. Ühendkuningriigis otsustas arvutiteaduses ebakompetentse mehaanikateadlase Sir James Lighthilli juhitud kõrge komisjon, et tehisintellekti ei ole ega tule. Selle tagajärge nimetatakse Ühendkuningriigis tehisintellekti talveks. Donaldi labor jäi rahata ja lagunes laiali.
Uus tehisintellekti tõus toimus kaheksakümnendatel aastatel. Nimelt oli möödunud sajandi kaheksakümnendate aastate alguseks tekkinud juba hulgaliselt näiteid kasulikest ekspertsüsteemidest. Sellisteks olid näiteks geoloogilisi andmeid interpreteerivad ja sellega geolooge abistavad ekspertsüsteemid, mis andsid suurt tulu naftaväljade kavandamisel. Valdkondi, kus ekspertsüsteemid osutusid kasulikuks, tuli üha juurde. Edulugusid jätkus küllaga ning see tekitas ettevõtjates suuri ootusi. Tekkis ekspertsüsteemide arenduse mull. Tehisintellekti üheksandal rahvusvahelisel konverentsil (IJCAI IX), mis toimus Los Angeleses 1985. aastal, oli osavõtjaid üle kuue tuhande. Nende hulgas oli küllalt palju ettevõtete esindajaid, kes lootsid luua endale kasulikku ekspertsüsteemi. Nii lõppes tehisintellekti talv ka Suurbritannias ja Donald Michie lõi peagi endale uue instituudi, mis sai tema sõbra mälestuseks nimeks Turingi instituut. Seal uuriti nii roboteid kui ka ekspertsüsteeme.
Tehismõistus tänapäeval
Tänu riistvara ja algoritmide arengule on sel sajandil tekkinud tähelepanuväärseid infotehnoloogia rakendusi, mille juures on kahtlemata märgata intelligentsust. Loeksin siia kuuluvaks eelkõige isesõitvad autod, samuti robotid ning tõlke-, male- ja mälumänguprogrammid. Näiteks võitis programm Watson 2011. aastal järjest kahes matšis maailma tugevamaid mälumängijaid Brat Rutterit ja Ken Jenningsit, saades auhinnarahaks miljon dollarit. Küsimused esitati mängijatele inimkeeles, mida Watson pidi seega mõistma. Watsoni kasutada oli suur andmemaht entsüklopeediatest, sõnaraamatutest ja Wikipediast. Seejuures sõnaraamatu „Urban Dictionary“ lisamisel juhtus ka omapärane lugu. Nimelt selles sõnaraamatus leidub hulgaliselt sündsusetuid väljendeid ning Watsonit ei suudetud keelata neid kasutamast, nii et kogu see sõnaraamat tuli Watsoni mälust kustutada.
Kui meenutada Alan Turingi 1950. aastal välja pakutud testi arvutite intelligentsuse hindamiseks, siis selle läbib Watson mälumängus kindlasti edukalt. Testiks on vestlus inimkeeles, mille käigus hinnatakse, kas on võimalik eristada arvuti vastuseid inimese omadest. Watsoni puhul on ju nii, et tema vastused „Jeopardy!“ (saateformaadil põhines ka Kanal 2 kavas olnud „Kuldvillak“ – toim) mängus on sama head või isegi paremad kui tema konkurentide omad. Nagu mälumängus ikka, on vastuste formaat seejuures üsna standardne, seega vastuste vormi kaudu ei ole eristamine võimalik.
Arvutite hiljutised muljetavaldavad saavutused inimtegevuse matkimises on viinud selleni, et on tekkinud järjekordne tehisintellekti buum. Kas see kujuneb ka lõhkevaks mulliks, ei ole veel aru saada. Käesoleva buum on suurel määral põhjustatud ootustest õppivate tehislike närvivõrkude eduka kasutamise kohta. Suuri lootusi pannakse uute tehislike närvivõrkude arendamisele.
Juba möödunud sajandi neljakümnendatel aastatel juhtisid loogikud tähelepanu sellele, et närvivõrkudes toimuvat saab analüüsida loogika vahenditega. Eriti tuleks aga esile tõsta möödunud sajandi loogika suurkuju Steven Kleene põhjalikku aruannet selle kohta, kuidas närvivõrkudes esitada nii loogika valemeid kui ka ajas toimuvaid ja loogikas kirjeldatud protsesse.1 See umbes sajaleheküljeline aruanne väärib lugemist kõigil, kes tegelevad või kavatsevad hakata tegelema närvivõrkudes toimuva uurimisega. Kui eeldada, et ajus toimub just infotöötlus, siis oleks Kleene töö edaspidise aju uurimise aluseks kõige sobivam. Ainus takistus võib olla selle töö ideede matemaatiliselt küllalt detailne esitus, mis nõuab lugejalt teatud matemaatilist haritust.
Kui küsida aju-uurijate käest, kuidas täpselt on minu ajus esitatud mulle just äsja teatatud kuuekohaline telefoninumber, siis jäävad nad mulle vastuse võlgu. Kuid see on alles lihtsamat sorti küsimus, millel on mõtet, kui lähtume sellest, et ajus toimub infotöötlus, mille tulemust me nimetame mõtlemiseks. Sel juhul on kõigest toimuvast arusaamiseks paratamatult vaja teada seda, kuidas on info ajus esitatud. Keerukam oleks vastata küsimusele, kuidas mu aju toimib, kui ma liidan peast kas või kahekohalisi kümnendarve. Selle kohta andis abstraktsel tasemel põhimõttelise seletuse küll juba ammu Steven Kleene, kuid selle seletust täpsustada ei ole kuuekümne aasta jooksul veel õnnestunud. Selline on seis meie teadmistega närvivõrkudest. Aju-uurijad teavad küll juba seda, milline aju osa üht või teist andmetöötluse toimingut teeb, seda saab teada EEG ja aju tomograafia kaudu. Kuid need teadmised on sarnased sellega, et arvutiekspert teab, milline kiip arvutis on mälu ja milline on protsessor. See ei anna kahjuks veel aimugi andmeid töötlevatest protsessidest ega sellest, kuidas neid kirjeldavad algoritmid on esitatud.
Kolm vaadet tehismõistusele
Tehismõistusele võib läheneda kolmest küljest:
• filosoofiliselt – küsides, kas masin mõtleb, kas masin saab olla oma loojast targem jms;
• tehniliselt – uurides ja arendades meetodeid ja vahendeid, mis võimaldavad luua intelligentseid rakendusi;
• rakenduslikult – luues intelligentseid rakendusi, nt isesõitvad autod või head maleprogrammid, kasutades seejuures juba olemasolevaid tehisintellekti meetodeid.
Esimese puhul tuleb kõigepealt kokku leppida mitme mõiste tähenduses, mida me küll kasutame, kuid defineerida õieti ei oskagi. Näiteks tuleb küsida, mis see mõistus, intellekt ja mõtlemine siis õieti ikka on. Alles seejärel osutub mõttekaks küsimus „kas masin mõtleb?“. Kuigi sellised küsimused on huvitavad ja vahest olulisedki, meie nendega siin ei tegele kas või seetõttu, et ei ole leidnud vajalikke usaldusväärseid definitsioone. Kui mõtlemine on defineeritud kui teatud tüüpi inimtegevus, siis on vastus küsimusele kindel ei. Seda isegi juhul, kui arvuti lahendab kõiki mõtlemisega seotavaid ülesandeid inimesest paremini.
Teine valdkond pakub juba praktilist huvi. Siin saame kindlalt osutada mitmele saavutusele. Eelkõige võime nimetada uusi masinõppe meetodeid, mis põhinevad suure hulga andmete kasutusel. Võtmesõnaks on siin süvaõpe (ingl deep learning). Selle idee esitas küll ammu Mihhail Bongard oma raamatus masinõppe kohta,2 mis ilmus nii vene kui ka inglise keeles. Kuid selle head rakendused said võimalikuks alles nüüd, mil arvutite võimsus on juba piisav.
Süvaõppe idee on selles, et õppimist korraldatakse kahel (või veelgi enamal) tasemel, sellest ka nimetus süvaõpe. Suure hulga näidete põhjal leitakse esimesel tasemel nende näidete seast küllalt sageli esinevad mustrid. Neid mustreid kasutades, võime öelda, et nende mustrite ehk mõistete keeles, esitatakse näited uuesti. Nii saadakse hoopis sisukamad ja lühemad näidete kirjeldused. Nüüd saab teisel tasemel uuesti korraldada õppimist, kuid juba kasutades näidete palju paremaid kirjeldusi. Kui on tegemist nägude äratundmisega, siis esimesel tasemel peaks tekkima mustritest sellised mõisted nagu nina, silmad, suu, kõrvad jne. Neid uusi mõisteid kasutades ja neid iseloomustades saab siis teisel tasemel nägusid kirjeldada.3 Näiteks võib näo kohta öelda, et see on suure suu, kõvera nina ja suurte kõrvadega. Süvaõpet osatakse teha isegi õppivaid närvivõrke kasutades.
Ka muud tehisintellekti meetodid on vahepeal arenenud. Ekspertsüsteemide tehnika on täienenud, neile lisatakse suuri teadmisbaase, nagu see oli mälumänguprogrammi Watson korral. Ekspertsüsteeme võib kohata väga mitmes rakenduses. Koos süvaõppega on need osutunud väga kasulikuks. Tulles tehisintellekti kolmanda, s.t rakendusliku käsituse juurde, nimetame eelkõige roboteid, mis saavad üha targemaks. Samuti on tehisintellekt oluline masinnägemise ja inimkeele mõistmise juures.
Tehislik üldine intellekt
Kui rääkida arvutite intelligentsuse valdkonnast üldiselt, siis rakenduslikust tehisintellektist on sisu poolest väga erinev tehisliku üldise intellekti mõiste (ingl artificial general intelligence, AGI). Selle all mõistetakse arvuti (või roboti) universaalsust – võimet sooritada kõiki intelligentsust nõudvaid toiminguid, mida suudab teha inimene. Seda nimetatakse ka tugevaks tehisintellektiks või täielikuks intellektiks. Sellise võime loomise katseid on tehtud juba aastakümneid. Üheks esimeseks sellealaseks projektiks võib lugeda Douglas Lenati projekti „Cyc“, mis sai alguse 1984. aastal.
Võime arutleda selle üle, mida tugeva tehisintellekti jaoks vaja on. Kindlasti on vaja teadmisi, ning nende omandamise võimet – õppimisvõimet. Peale selle on vaja oskust neid teadmisi kasutada. Oskused saavad ilmselt olla programmide kujul. Esitavad ju programmide kirjeldatud algoritmid just andmetega ümberkäimise oskusi. Teadmiste ja oskuste kohta käivate väidete paikapidavust toetab ka ekspertsüsteemide ehitus: neis on teadmisbaas selles sisalduvate teadmistega, mida kasutab vastavate oskustega tuletusmehhanism.
Teadmiste omandamise ja hoidmise osas paistab olevat häid tulemusi. Seda näitab nii Googleʼi kui ka programmi Watson edu oma laiade teadmiste omandamisel ja kasutamisel. Eriti paistab silma Googleʼi teadmiste kogumise võime. Kõik, mis satub veebi, saab kättesaadavaks ka Googleʼile.
Halvem lugu on teadmiste kasutamisega. Nii Googleʼil kui Watsonil on küll universaalseid teadmisi, kuid teadmiste kasutamiseks rakendavad nad neile varem inimeste poolt programmidena antud oskusi. Meie võime mis tahes programmi vaadelda kui mingite oskuste esitust.4 Väidab ju algoritmi definitsioongi seda, et algoritm on tegevuse eeskiri, aga programm on algoritmi kirjeldus. Seega lisandub arvutisse pidevalt oskusi, sest programme tuleb üha juurde. Siin võiks näha analoogiat sellega, kuidas Google saab pidevalt juurde teadmisi inimeste täiendatavast veebist. Kuid siin on ka erinevus: Google oskab saadud teadmisi ka kasutada, andes meie küsimustele järjest paremaid vastuseid. Seevastu arvutid ei oska neisse kogunevate programmidega ise midagi peale hakata.
Me võime programmide arvutisse lisamist võtta kui arvuti õpetamist. Selles mõttes on arvuti väga hea õppija teda õpetavale tarkvara arendajale. Kõik, mis arvutile on esitatud, jääb talle meelde ega kao kuhugi. Kuid selline õppija on vilets teadmiste rakendaja – ise ta ei oska saadud teadmisi kasutada: talle tuleb öelda, et võta nüüd see programm. Seepärast läheb juba olemasolevate programmide kasutamiseks vaja inimese abi, kas või arvutile skriptide kirjutamiseks. Oskuste automaatseks arvutis kasutamiseks jääb midagi väga olulist ikka veel puudu.
Arvutite üliintelligentsuse müüt
Tehisliku üldise intellekti loomise ebaedust hoolimata on tekkinud arvutite peatse üliintelligentsuse müüt. Juba arvutite algaastatel oli kahtlusi, kas arvutid ei saa liiga targaks ja sellega inimestele ohtlikuks. See teema sai populaarseks möödunud sajandi kaheksakümnendatel aastatel, mil oli tehisintellekti buum. Ka viimasel kümnendil on tekkinud samalaadne olukord: tehisintellekti järjekordse buumi ajal on sama küsimus jälle üleval.
Ilma sügavamalt sisusse tungimata nähakse järgmist võimalikku tehisintellekti arengut. Tarkuse kogunemine arvutitesse võib toimuda ajas eksponentsiaalselt kiirenevalt, s.t väga kõvasti kiirenevalt. Sellisel arvamusel on alust, kui võtta arvesse, et arvuti tarkuse lisandumine teeb arvuti õppimise hõlpsamaks ja ilmselt ka kiiremaks. See võib teoreetiliselt viia olukorrani, mil arvutite targemaks saamine muutub teatud hetkel plahvatuslikult tohutu kiireks ja läheb täielikult inimeste kontrolli alt välja. Sellise olukorra nimetus on tehnoloogiline singulaarsus. Sõna singulaarsus tähistas seni küll matemaatikas mõne funktsiooni sellist kohta, kus funktsiooni käitumine on väga iseäralik. Igatahes asutasid USA entusiastid isegi singulaarsuse instituudi (Singularity Institute või Singularity University), mis, tõsi küll, 2013. aastal sai tagasihoidlikuma nimetuse masinintellekti uurimisinstituut (Machine Intelligence Research Institute, MIRI). Mõnede prognooside järgi peaks 2040. aastal toimuma isegi see, et arvutid võtavad võimu enda kätte.
On teada ka tehnoloogilise singulaarsuse peatse saabumise vastu rääkivaid fakte. Kui mitte arvestada universumi teket suure pauguga, siis pole seni ühelgi juhul sellesarnast singulaarsuse olukorda tekkinud, ei looduses ega tehnikas. Isegi kui mõnel juhul teatud arengufaasis on olnud märgata eksponentsiaalset arengut, on alati leidunud mingid mõjud, mis hakkasid eksponentsiaalset arengut piirama. Seetõttu tavaliseks ajas arengut näitavaks kõveraks on niinimetatud sigmoid – S-kujuline kõver, mis näitab, et teatud ajahetkest alates areng aeglustub. Vaadeldava tehnoloogilise singulaarsuse piirajateks võiksid saada mitmesuguste ressursside piirangud, olgu üheks selliseks kas või energia. Inimaju on ikkagi energeetiliselt väga ökonoomne infotöötlusvahend, millesarnaseid ei ole tehnika seni veel pakkunud.
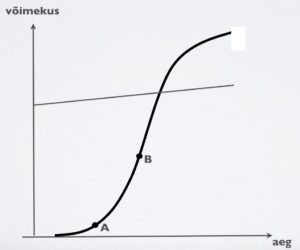
S-kujuline arengukõver on näidatud juuresoleval joonisel. Nüüd on küsimus selles, millises kohas arvutid oma arenguga on: kas punktis A või punktis B. Esimesel juhul on masinatel veel palju arenguruumi, teisel juhul vähem. Kaldjoon tähistab sellel joonisel inimese võimekust, mis küll aja jooksul kasvab, kuid seda tunduvalt vähem kui arvutite võimekus. Seda on seni näidanud meile tegelikkus. Selle joonisega seoses tekib veel üks küsimus: kas näitasime inimese võimekust ikka õigel kõrgusel? Sellel joonisel on näha kahe joone lõikepunkt, mis tähistab, et arvutite võimekus saab sel hetkel inimeste omaga võrdseks ja edaspidi ületab seda. Kui oleksime inimese võimekust näitava joone pannud nii kõrgele, et see ei lõiku sigmoidiga, oleks tulevik selline, et arvutid ei saa kunagi targemaks kui inimesed. Keegi ei tea selle joone õiget kohta.
Joonisel ei ole ühtegi arvu. Põhjuseks on see, et me ei oskagi hinnata inimese ja arvuti võimekust arvuliselt. Pealegi ei ole me kokku leppinud selles, mida võimekus tähendab. On see tarkus, intelligentsus, oskused? Isegi ajateljele ei saa me paigutada käesolevat hetke tähistavat aastat. On see punkti A või B kohal? Seega kirjeldab joonis küll võimalikku arengut põhimõtteliselt, kuid ei anna meile mingit võimalust täpsemateks prognoosideks. Me ei saa selle põhjal ka vastata küsimusele, kas arvuti muutub inimesest targemaks. Kuid ettevaatust: küberohte on küllalt palju ka juhul, kui nii võimsat vahendit nagu arvuti kasutatakse ainult kui intelligentset abilist.
1 Steven C. Kleene, „Representation of Events in Nerve Nets and Finite Automata“ – Project RAND Research Memorandum– RM 704, 1951.
2 Mihail Bongard, „Pattern recognition“. Spartan Books; First Edition 1970.
3 Tegelikult inimesed üldjuhul ei teagi, millised mustrid õppiv programm leidis, ja need ei pruugi hoopiski antud juhul olla ninad või silmad.
4 Programmide käsitlemine oskuste kirjeldustena on ilmekalt näha robootikas. Robot oskab midagi teha siis, kui tal on selleks olemas programm.