

Privaatsust säilitav andmeanalüüs
Digitaalne kirje luuakse inimese kohta kohe pärast tema sündi. Sellest alates jälgitakse tema elukäiku ja kogutakse andmeid eri eluvaldkondade kohta. Riigiasutused haldavad infot oma kodanike tervise, hariduse ja sissetulekute kohta, et neid paremini ravida, harida ja neilt makse koguda. On arusaadav, et riik toimib paremini, kui tal on korralik ülevaade oma elanikkonnast. Teisest küljest muudavad elektroonilised andmekogud ka inimeste elu lihtsamaks. Lepingute sõlmimine, ülikooli sisseastumine, sissekirjutuse muutmine ja apteegist retseptirohtude ostmine on viimase kümne aastaga palju kergemaks läinud.
Nii on meie privaatsuse hinnaks toimiv ühiskond ja mitmesugused mugavused, mida riigiasutused meile andmete eest pakuvad. Kogu selle protsessi käigus me eeldame, et andmeid kasutatakse mõistlikult ning et riik hoolitseb meie andmete privaatsuse tagamise eest. Eestis kehtiv isikuandmete kaitse seadus on kehtestanud isikuandmete töötlemisele selged piirid.
Mis on privaatsuse hind?

Joonis 1. Turvaline ühisarvutus on krüptograafiline meetod, mis lubab analüüsida andmeid nii, et üksikuid väärtusi ei ole kunagi võimalik näha.
Kui riigi kogutavate andmete puhul on kodanikule tegemist ikkagi paratamatusega, mis on demokraatlikult paika pandud, siis tegelikult anname väga palju oma privaatsusest ja andmetest ära täiesti vabatahtlikult. Vahel tehakse seda teadlikult, vahel sellele mõtlemata. Üldiselt me ikkagi loodame saada mingit kasu vastutasuks oma andmete eest, aga on juhtumeid, kui jääb selgusetuks, miks on vaja kõiki neid andmeid ning mida ikkagi inimene vastu saab.
Mobiilioperaatoriga lepingut sõlmides annab isik talle oma otsesed andmed, aga tegelikult saab ettevõte päris palju kaudset informatsiooni, millele klient esmajoones ei mõtle. Selleks et teenust pakkuda, registreerib ka kõige lihtsam mobiiltelefon ennast lähimasse masti, seega on mobiilimasti andmetest väga kerge välja lugeda, kus ja kuidas inimene päeva jooksul liigub. Klient ei tea, kas andmed salvestatakse ja mida, kui üldse, nende andmetega ette võetakse. Mobiiltelefonide puhul on ju kõigile selge, missugust kasu ja mugavust see teenus meile pakub. Vahel ikka meenutame, kuidas saadi kokku kella all ja mis tunne oli, kui sõber kümme minutit hilines. Seega oleme vahetanud oma privaatsuse mobiilsuse vastu.
Küll aga ei ole alati selge hind, mille eest ostja oma andmed poekettidele annab. Kliendikaartide kasutustingimused erinevad: pakutakse kohe allahindlust, punktide kogumist või kampaania allahindlusi. Klient teeb teadliku otsuse ja annab oma nime, sünniaja, aadressi, telefoninumbri. Pole teada, miks ettevõte vajab kliendi aadressi või telefoninumbrit, aga ankeedis on see kohustuslik väli. Esmapilgul ei olegi kuigi palju informatsiooni ja kui iga poeskäiguga on võimalik paar eurot kokku hoida, tundub see mõistlik. Aga poekett salvestab ka kõik ostud. Nende andmete pealt võib teha väga huvitavaid analüüse ja andmekaevet ning pood saab sellest kasu näiteks oma kaupu ümber paigutades ning siis jälgides, kuidas muutub ostukäitumine.
Kas olete mõelnud, miks on leib ja piim poe kõige tagumistes (ja tavaliselt erinevates) nurkades? Ostuinfo aga reedab kliendi kohta kaudselt juba nii mõndagi, mida poel ei ole vaja teada, näiteks kui inimene hakkab järsku ostma mähkmeid. Lisavõimalusena on mõnes poes võimalik ka oma saabumine registreerida. Enne poodi sisenemist saab tõmmata kliendikaardi läbi masina, mis annab personaalseid soodustusi, mida ilma masinat kasutamata ei saa. Lisainfo, mida klient poele sellise käitumisega annab, on see, kui kaua ta poes aega kulutab, et oma ostukorv kokku panna. Tõenäosus, et iga kord on pakkumistes midagi kliendile vajalikku, on väike ning seega müüb ta seda lisainfot üpris odavalt.
Hiljuti sain ühelt rõivapoelt kupongi, mis lubas mulle 20% soodustust järgmiselt üle 30euroselt ostult ainult minu isikuandmete hinnaga. All oli klausel, et minu andmeid (kaasa arvatud telefoninumbrit) kasutatakse ainult otseturunduse eesmärgil. See kupong ei lubanud mulle midagi muud peale ühekordse soodustuse ja ilmselt rämpsposti.
Kontroll andmete üle
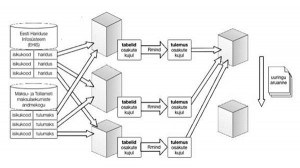
Joonis 2. Uuring, mille eesmärk on teada saada, kas tudengid, kes õpingute ajal töötavad, lõpetavad nominaalajaga väiksema tõenäosusega kui nende õpingutele keskenduvad kaaslased. Haridus- ja teadusministeeriumist ning maksu- ja tolliamet jagavad iga tudengi töötamise ja õppimise andmete väärtuse lähtekohas kolmeks tükiks ning saadavad need tükid kolmele arvutavale osalejale. Terviklikud kirjed ei välju kunagi originaalandmekogudest ja see tagab kaitse ka seaduse silmis.
Kui oma andmed mõnele ettevõttele või veebilehele ära anname, kaotame kontrolli nende leviku üle. Isegi kui ettevõte lubab, et kasutab andmeid ainult teenusepakkumiseks ning töötleb neid isikustamata kujul, peab inimene usaldama, et ettevõte ka nii käitub. Eraisik ei saa olla kindel, kas ettevõte ka tegelikult töötleb andmeid vastavalt seadusele. Ka riik ei jõua kõiki andmeid koguvaid ettevõtteid kontrollida, liiatigi on tihti tegemist välismaiste ettevõtetega, mis ei allu Eesti või Euroopa Liidu seadustele.
Kodanikul on õigus nõuda oma andmete andmebaasidest kustutamist, aga see ei ole nii lihtne, kui paistab.
Olen saanud sooduspakkumistega mobiilisõnumeid ühelt poeketilt (kuigi tean, et ankeeti olin märkinud, et neid ei soovi) ning pärast viit palvet mulle sõnumeid mitte enam saata saavutasin lõpuks pärast seaduse mainimist oma tahtmise.
Millised andmed identifitseerivad isiku?
Seadust järgivate ettevõtete puhul on ligipääs andmetele piiratud, ainult volitatud töötlejad näevad üksikisiku kirjeid. Teisalt on andmete kogumisel mõtet ainult siis, kui neid ka analüüsitakse ning järelduste põhjal midagi ette võetakse. Selleks et ühiskonna või klientuuri kohta järeldusi teha, ei olegi tegelikult vaja, et andmed oleksid isikuga seotud, piisab, kui ühe inimese kirjed on omavahel mingi identifikaatoriga ühendatud. Protsessi, kus inimest identifitseerivad kirjed eemaldatakse andmekogust ning asendatakse mingi koodiga, nimetatakse anonümiseerimiseks.
Anonümiseerimise puuduseks on see, et väga raske on andmekogu kirjelduse põhjal teha kindlaks, mis on inimest identifitseerivad kirjed. Kui eemaldada isikukood, nimi, aadress ja telefoninumber, siis võib ikkagi alles jääda komplekt kirjeid, mis isiku kindlaks määravad. Näiteks olen ma hetkeseisuga ainus 2015. aastal töö kaitsnud doktor Tartu ülikooli arvutiteaduse instituudis. Sel aastal tuleb doktoreid kindlasti veel, aga kui originaalses andmestikus on alles näiteks sugu ja vanus, siis see määrab ikkagi mu üheselt ära. Ühe asutuse siseselt saab analüüsi teha analüütik, kellel on andmete töötlemise luba. Palju huvitavamaid tulemusi võib aga pakkuda statistiline uuring, kus käsitletakse mitme asutuse andmeid. Siis võib tekkida probleem, et ei ole sellist üht analüütikut, kes tohib töödelda mõlema asutuse andmeid.
Euroopa Liidu andmekaitsedirektiivides on erilise tähelepanu all isiku geneetilised andmed, mis on väga delikaatsed, sest kannavad meie kohta väga palju informatsiooni. Samal ajal on neis peidus nii palju huvitavat, mida oleks võimalik varasel diagnoosimisel ja ravimisel ära kasutada. Seega on huvi geeniandmete analüüsi vastu väga suur. Ameerika Ühendriikides andis riiklik terviseinstituut (National Institute of Health, NIH) avalikult välja DNA-segude andmed, et nende põhjal oleks võimalik teha teadusuuringuid. Katsete käigus ilmnes aga hoopis, et selliste segude puhul on võimalik tuvastada, kas konkreetse isiku DNA on segus olemas või mitte. Kuna segud on tehtud mingi tunnuse (nt haiguse olemasolu) põhjal, siis selline avastus rikub andmekaitse nõudeid ning NIH võttis andmed maha. See aga omakorda kaotas võimaluse kasutada andmeid teadusuuringutes.
Turvaline ühisarvutus ja statistiline analüüs
Oma doktoritöös uurisin, kuidas teha statistilist analüüsi nii, et üksikisiku privaatsus oleks tõestatavalt tagatud. Sellist analüüsi on võimalik teha turvalise ühisarvutuse abil. Turvaline ühisarvutus on krüptograafiline meetod, mis lubab analüüsida andmeid nii, et üksikuid väärtusi ei ole kunagi võimalik näha. Näiteks võib isiku vanuse ühissalastuse abil jagada kolmeks juhuslikuks osakuks nii, et osakute summa annab kokku vanuse, aga osakud eraldi ei reeda midagi algse väärtuse kohta (vt joonis 1). See on nagu kolme tükiga pusle – üks tükk ei anna pilti, aga kui kõik kolm kokku panna, on pilt käes. Niimoodi jagatakse tükkideks kõik isiku kohta käivad väärtused ning osakud saadetakse sõltumatutele ühisarvutuse osalistele. Igale osalisele tekib andmebaas juhuslike arvudega. Turvalise ühisarvutuse parim omadus on see, et neid jagatud väärtusi on võimalik omavahel liita, lahutada, korrutada ja võrrelda, ilma et oleks vaja väärtusi kokku tagasi panna. Arvutuste lõpus liidetakse kokku lõpptulemuse osakud. Seega on saadud kätte vastus, ilma et üksikuid väärtusi oleks vahepeal pidanud avaldama.
Selline andmete jagamine osalejate vahel hajutab ka usaldust, mida eraisik peab andmeid koguva ettevõtte vastu ilmutama. Nüüd ei tarvitse tal usaldada üht kindlat ettevõtet, vaid ta peab usaldama üht ettevõtet kolme hulgast – tõenäosus, et kolm ettevõtet kolmest on pahatahtlikud, on väiksem.
Tuginesin oma töös Cybernetica ASi ja Tartu ülikooli koostöös välja töötatud turvalise ühisarvutuse platvormile Sharemind, mis oskab teha eespool mainitud tehteid. Uurisin, kas sedasi jagatud andmete peal on võimalik kasutada populaarseimaid statistilise analüüsi meetodeid. Minu töö kirjeldab, kuidas on võimalik kohandada algoritme nii, et need töötaksid ühissalastatud väärtustel ilma privaatsust kaotamata.
Minu koostatud algoritmide põhjal töötas meie teadusrühm välja privaatsust säilitava statistilise analüüsi tööriista nimega Rmind, mis sarnaneb statistikute tavapäraste töövahenditega. Rmind lubab neil korraldada uuringuid, ilma et nad peaksid üksikasjalikult tundma allolevaid krüptograafilisi protokolle. Nii saab analüütik kasutada privaatsust säilitavaid meetodeid sarnaselt oma tavapärase tööprotsessiga. Ta ei pea teadma, kuidas kasutatav analüüsimeetod krüptograafiliselt töötab ja saab keskenduda tulemusele.
Privaatsust säilitav statistika praktikas
Loodud algoritmide ning Rmindi abil on võimalik teha nii privaatsust säilitavat geenianalüüsi kui ka riigiasutustevahelisi analüüse. Et uurida, kas meetodid ka praktikas kasutatavad on, teeme praegu statistilist uuringut, mille eesmärk on teada saada, kas tudengid, kes õpingute ajal töötavad, lõpetavad nominaalajaga väiksema tõenäosusega kui nende õpingutele keskenduvad kaaslased. Selleks vajame andmeid haridus- ja teadusministeeriumist ning maksu- ja tolliametist. Need asutused jagavad iga tudengi töötamise ja õppimise andmete väärtuse lähtekohas kolmeks tükiks ning saadavad need tükid kolmele arvutavale osalejale (vt joonis 2). Terviklikud kirjed ei välju kunagi originaalandmekogudest ja see tagab kaitse ka seaduse silmis. Kirjeldatud meetodi sobivust andmekaitseks on kinnitanud Eesti andmekaitse inspektsioon.
Arvutavateks osalejateks on meie uuringus riigi infosüsteemi amet (RIA), rahandusministeeriumi infotehnoloogiakeskus ja Cybernetica AS. Selleks et andmete peal saaks arvutusi teha, peavad kõik olema nõus tegema statistiku kirjeldatud päringuid. Nii on maksuametil võimalik kontrollida, mida nende jagatud andmete peal tehakse, samal ajal ei ole neil ligipääsu haridusministeeriumi andmetele. Teised – RIA ja Cybernetica – ei näe samuti, milliste andmetega on tegu. Päringuid teeb statistik rakendusuuringute keskusest CentAR. Tema kasutabki tööriista Rmind, mis oskab viia tavapärase statistilise päringu sellise kujule, et seda oleks võimalik teostada ühissalastatud andmete peal. Tulemuste põhjal paneb CentAR kokku aruande, mille tellijaks on Eesti Infotehnoloogia ja Telekommunikatsiooni Liit (ITL), kellele on IT-tudengite käekäik väga oluline.
See on maailmas esimene sellises mahus statistiline uuring, mida tehakse ühissalastatud andmete peal. Nimelt on ühissalastatud andmete peal töötamine aeglasem kui salastamata andmete peal. Seetõttu pole varem kuskil seda proovitud teha. Meie uuringus on haridusministeeriumi andmeid rohkem kui 600 000 andmekirjet ning maksuametist umbes 10,5 miljonit andmekirjet.
Töö Rmindi ja Sharemindi arendamiseks jätkub ning loodame juba lähiaastatel neid tööriistu veel rakendada nii Eestis kui ka välismaal.
Loe Sirpi!

Esiküljel antropoloog Aet Annist. Foto Piia Ruber
Tarmo Soomere, „Eesti hariduse tähendusrikas lähiajalugu“
Intervjuu Leedu arhitekti Gilma Teodora Gylytėga
Päiv Dengo „Kilpkonn üheks päevaks“
Sirpa Kähköse „36 urni. Eksimiste ajalugu“
Mart Kangro „Põhineb tõestisündinud lool. Päriselt-päriselt“
lühilavastuste õhtu „SAAL3 vol. 3“
Taavi Suisalu näitus „Arktika saatkond“
Läti teatri esitlusfestival „Skate“
Järgmine Sirp ilmub 10. jaanuaril.
Värsked artiklid
Leia veel huvitavat lugemist













